Oracle LOB圧縮③ [DBMS]
LOBセグメント圧縮の続きです。
せっかくなので簡単に検索性能の比較もしてみます。
テーブルの詳細は前回を見て頂くとして、簡単に以下の様になってます。
DDNTF……セキュアファイルで圧縮なしのLOBを含むテーブル
ZDDNTF …セキュアファイルでMEDIUM圧縮のLOBを含むテーブル
Z2DDNTF…セキュアファイルでHIGH圧縮のLOBを含むテーブル
Z3DDNTF…ベーシックファイルで圧縮なしのLOBを含むテーブル
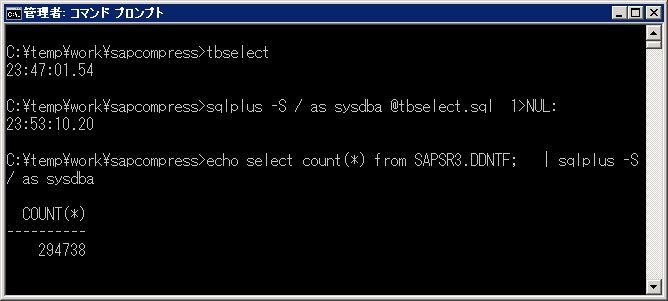
検索に使うSQLファイルの中身は以下です。SAPSR3はスキーマで、テーブル名のみ変更して使います。
SET HEAD OFF
SET PAGESIZE 0
select * from SAPSR3.DDNTF;
exit
まずは元のテーブル セキュアファイルで圧縮なしの検索です。
約6分9秒でした。
せっかくなので簡単に検索性能の比較もしてみます。
テーブルの詳細は前回を見て頂くとして、簡単に以下の様になってます。
DDNTF……セキュアファイルで圧縮なしのLOBを含むテーブル
ZDDNTF …セキュアファイルでMEDIUM圧縮のLOBを含むテーブル
Z2DDNTF…セキュアファイルでHIGH圧縮のLOBを含むテーブル
Z3DDNTF…ベーシックファイルで圧縮なしのLOBを含むテーブル
検索に使うSQLファイルの中身は以下です。SAPSR3はスキーマで、テーブル名のみ変更して使います。
SET HEAD OFF
SET PAGESIZE 0
select * from SAPSR3.DDNTF;
exit
まずは元のテーブル セキュアファイルで圧縮なしの検索です。
約6分9秒でした。
Oracle LOB圧縮② [DBMS]
今回はLOBセグメントを実際に圧縮してみます。


まずは元のテーブルの情報で、下の様に作られています。
テーブル名 DDNTF
スキーマ名 SAPSR3
項目 FIELDS を BLOB で SECUREFILE の NOCOMPRESS で テーブル本体と LOB 両方ともテーブルスペース PSAPSR3 に作っています。
CREATE TABLE "SAPSR3"."DDNTF"
( "TABNAME" VARCHAR2(90) DEFAULT ' ' NOT NULL ENABLE,
"BLOCKNR" NUMBER(3,0) DEFAULT 0 NOT NULL ENABLE,
"FIELDSLG" NUMBER(5,0) DEFAULT 0 NOT NULL ENABLE,
"FIELDS" BLOB
)
PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 COMPRESS FOR OLTP LOGGING
STORAGE(INITIAL 207839232 NEXT 10485760 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "PSAPSR3"
LOB ("FIELDS") STORE AS SECUREFILE (
TABLESPACE "PSAPSR3" ENABLE STORAGE IN ROW CHUNK 8192
CACHE LOGGING NOCOMPRESS KEEP_DUPLICATES
STORAGE(INITIAL 106496 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)) ;
まずは元のテーブルの情報で、下の様に作られています。
テーブル名 DDNTF
スキーマ名 SAPSR3
項目 FIELDS を BLOB で SECUREFILE の NOCOMPRESS で テーブル本体と LOB 両方ともテーブルスペース PSAPSR3 に作っています。
CREATE TABLE "SAPSR3"."DDNTF"
( "TABNAME" VARCHAR2(90) DEFAULT ' ' NOT NULL ENABLE,
"BLOCKNR" NUMBER(3,0) DEFAULT 0 NOT NULL ENABLE,
"FIELDSLG" NUMBER(5,0) DEFAULT 0 NOT NULL ENABLE,
"FIELDS" BLOB
)
PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 COMPRESS FOR OLTP LOGGING
STORAGE(INITIAL 207839232 NEXT 10485760 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "PSAPSR3"
LOB ("FIELDS") STORE AS SECUREFILE (
TABLESPACE "PSAPSR3" ENABLE STORAGE IN ROW CHUNK 8192
CACHE LOGGING NOCOMPRESS KEEP_DUPLICATES
STORAGE(INITIAL 106496 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)) ;
Oracle LOB圧縮① [DBMS]
圧縮と一言で言っても何を又は何処を圧縮するのか、Oracleの圧縮といってもいろいろあります。
データベースのデータ型にはLOB(LongOBject)型というのがあります。
昔はRAWとかLONGとかLONG RAWで使っていた型です。
数MB~4GB程度のデータを格納するためのデータ型でして、Oracleではこのデータ型の項目を別に管理していて、別の領域に格納します。
また、LOBにも主にバイナリデータを扱う BLOBとテキストデータを扱う CLOBがあります。
以下の様なテーブルがあった場合、BLOBの項目だけ別の領域が作られて管理されます。
CREATE TABLE "SAPSR3"."ZDDNTF"
( "TABNAME" VARCHAR2(90) DEFAULT ' ' NOT NULL ENABLE,
"BLOCKNR" NUMBER(3,0) DEFAULT 0 NOT NULL ENABLE,
"FIELDSLG" NUMBER(5,0) DEFAULT 0 NOT NULL ENABLE,
"FIELDS" BLOB
);
データベースのデータ型にはLOB(LongOBject)型というのがあります。
昔はRAWとかLONGとかLONG RAWで使っていた型です。
数MB~4GB程度のデータを格納するためのデータ型でして、Oracleではこのデータ型の項目を別に管理していて、別の領域に格納します。
また、LOBにも主にバイナリデータを扱う BLOBとテキストデータを扱う CLOBがあります。
以下の様なテーブルがあった場合、BLOBの項目だけ別の領域が作られて管理されます。
CREATE TABLE "SAPSR3"."ZDDNTF"
( "TABNAME" VARCHAR2(90) DEFAULT ' ' NOT NULL ENABLE,
"BLOCKNR" NUMBER(3,0) DEFAULT 0 NOT NULL ENABLE,
"FIELDSLG" NUMBER(5,0) DEFAULT 0 NOT NULL ENABLE,
"FIELDS" BLOB
);
Oracle データ圧縮③ [DBMS]

データ圧縮で検索性能はほぼ差がない様でしたので、今回は挿入を見てみます。
検索で使ったテーブル D010TAB と同じ構造のテーブル ZD010TAB を作って、そこに insert into select で D010TAB の内容を ZD010TAB へ挿入します。
insert into "SAPSR3"."ZD010TAB" select * from "SAPSR3"."D010TAB";
挿入されるテーブルは予め空にしてから圧縮タイプを変更して、圧縮タイプでどう変わるか見てみます。
truncate table "SAPSR3"."ZD010TAB";
ALTER TABLE "SAPSR3"."ZD010TAB" MOVE NOCOMPRESS;
コピー元のテーブル D010TAB は圧縮なしで実施します。
Oracle データ圧縮② [DBMS]
前回からだいぶ間が空きました。
データ圧縮でそれなりに圧縮される様ですので、検索性能にどの程度オーバーヘッドが加わるのか見てみたいと思います。
とはいえ、テーブルの内容によってきっと変わるだろうから目安という事でお願いします。
Oracle 11g では基本圧縮(BASIC) と OLTP表圧縮(FOR OLTP) の2種類の圧縮方法があるので、圧縮なしの状態を含めてそれぞれの状態で検索します。
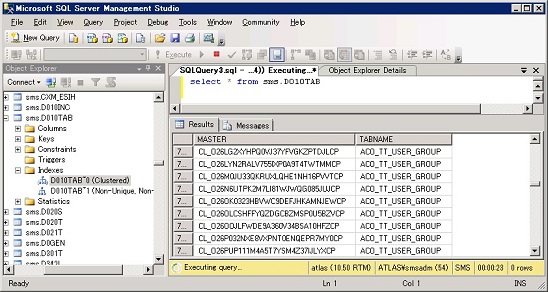
対象となるテーブルは以下の様に作られています。
CREATE TABLE "SAPSR3"."D010TAB"
( "MASTER" VARCHAR2(120) DEFAULT ' ' NOT NULL ENABLE,
"TABNAME" VARCHAR2(90) DEFAULT ' ' NOT NULL ENABLE
)
PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 COMPRESS FOR OLTP LOGGING
STORAGE(INITIAL 16384 NEXT 2621440 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "PSAPSR3701" ;
データは343,820件あります。
データ圧縮でそれなりに圧縮される様ですので、検索性能にどの程度オーバーヘッドが加わるのか見てみたいと思います。
とはいえ、テーブルの内容によってきっと変わるだろうから目安という事でお願いします。
Oracle 11g では基本圧縮(BASIC) と OLTP表圧縮(FOR OLTP) の2種類の圧縮方法があるので、圧縮なしの状態を含めてそれぞれの状態で検索します。
対象となるテーブルは以下の様に作られています。
CREATE TABLE "SAPSR3"."D010TAB"
( "MASTER" VARCHAR2(120) DEFAULT ' ' NOT NULL ENABLE,
"TABNAME" VARCHAR2(90) DEFAULT ' ' NOT NULL ENABLE
)
PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 COMPRESS FOR OLTP LOGGING
STORAGE(INITIAL 16384 NEXT 2621440 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "PSAPSR3701" ;
データは343,820件あります。
Oracle データ圧縮① [DBMS]
圧縮と一言で言っても何を又は何処を圧縮するのか、Oracleの圧縮といってもいろいろあります。
INDEXの圧縮からだいぶ間が空きましたが、今度はデータ圧縮をしてみます。
Oracle 11g では基本圧縮(BASIC) と OLTP表圧縮(FOR OLTP) の2種類の圧縮方法があります。
基本圧縮には EnterpriseEdition が必要で、OLTP表圧縮にはさらに Advanced Compression Option が必要になります。
INDEXの圧縮からだいぶ間が空きましたが、今度はデータ圧縮をしてみます。
Oracle 11g では基本圧縮(BASIC) と OLTP表圧縮(FOR OLTP) の2種類の圧縮方法があります。
基本圧縮には EnterpriseEdition が必要で、OLTP表圧縮にはさらに Advanced Compression Option が必要になります。
Oracle インデックス圧縮 [DBMS]
圧縮と一言で言っても何を又は何処を圧縮するのか、Oracleの圧縮といってもいろいろあります。
とりあえず、データの圧縮とインデックスの圧縮を見て行きたいと思います。
Oracleの場合、データの圧縮とインデックスの圧縮ではアルゴリズムが全く違いますので分けて見て行きます。
まずはインデックスの圧縮です。
Oracle 8i の頃からある機能だそうです。
こんなインデックスがあった場合、
以下の様に圧縮するそうです。
同じ項目を一まとめにして実際の容量を減らします。
圧縮したからといって伸張に時間がかかるという訳ではなく、インデックスのフルスキャンの時は実際に読み込む量が減るので、多少なりとも早くなる事が期待できます。
実際検索して検証しようとは思いましたが…データが用意出来なかったので今回は無しです。
インデックスが縮小されたからといって、テーブルスペースのサイズが縮小される訳ではないので、RMANとか使わないデータベースのバックアップ(データファイルのコピー)の時間が短縮されないのがちょっと微妙です。空き容量分、データファイルのリサイズで縮小しないと短縮されません。
とりあえず、データの圧縮とインデックスの圧縮を見て行きたいと思います。
Oracleの場合、データの圧縮とインデックスの圧縮ではアルゴリズムが全く違いますので分けて見て行きます。
まずはインデックスの圧縮です。
Oracle 8i の頃からある機能だそうです。
こんなインデックスがあった場合、
| 1 | A | X | 1 | A | 1 | DATA1 |
|---|---|---|---|---|---|---|
| 1 | A | X | 1 | B | 2 | DATA2 |
| 1 | A | X | 2 | A | 3 | DATA3 |
| 1 | A | Y | 1 | B | 4 | DATA4 |
| 1 | A | Y | 3 | C | 5 | DATA5 |
| 1 | A | Y | 3 | C | 6 | DATA6 |
| 1 | A | Y | 3 | D | 7 | DATA7 |
| 1 | B | X | 1 | A | 1 | DATA8 |
| 1 | B | X | 1 | A | 2 | DATA9 |
| 1 | B | X | 1 | C | 3 | DATA10 |
| 1 | B | X | 3 | A | 4 | DATA11 |
| 1 | B | X | 3 | C | 5 | DATA12 |
| 1 | B | X | 3 | C | 6 | DATA13 |
以下の様に圧縮するそうです。
| 1 | A | X | 1 | A | 1 | DATA1 |
|---|---|---|---|---|---|---|
| 1 | B | 2 | DATA2 | |||
| 2 | A | 3 | DATA3 | |||
| 1 | A | Y | 1 | B | 4 | DATA4 |
| 3 | C | 5 | DATA5 | |||
| 3 | C | 6 | DATA6 | |||
| 3 | D | 7 | DATA7 | |||
| 1 | B | X | 1 | A | 1 | DATA8 |
| 1 | A | 2 | DATA9 | |||
| 1 | C | 3 | DATA10 | |||
| 3 | A | 4 | DATA11 | |||
| 3 | C | 5 | DATA12 | |||
| 3 | C | 6 | DATA13 |
同じ項目を一まとめにして実際の容量を減らします。
圧縮したからといって伸張に時間がかかるという訳ではなく、インデックスのフルスキャンの時は実際に読み込む量が減るので、多少なりとも早くなる事が期待できます。
実際検索して検証しようとは思いましたが…データが用意出来なかったので今回は無しです。
インデックスが縮小されたからといって、テーブルスペースのサイズが縮小される訳ではないので、RMANとか使わないデータベースのバックアップ(データファイルのコピー)の時間が短縮されないのがちょっと微妙です。空き容量分、データファイルのリサイズで縮小しないと短縮されません。
SQL Server 2008R2 データ圧縮 その④ [DBMS]
前回は検索性能を見てみました。
メモリの使用量に違いはあったものの、時間的には大差ない結果でした。
今回は挿入を見てみます。
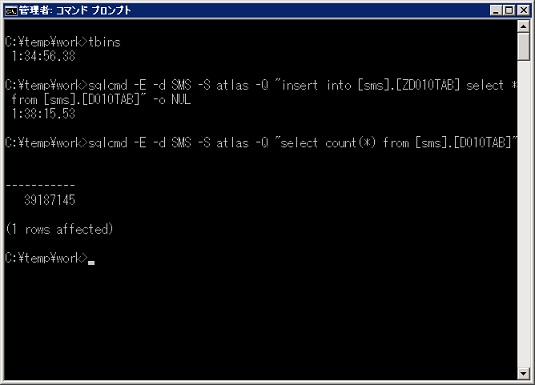
検索で使ったテーブル D010TAB と同じ構造のテーブル ZD010TAB を作って、
create table sms.ZD010TAB ( MASTER nvarchar(40) not null, TABNAME nvarchar(30) not null);
そこに insert into select で D010TAB の内容を ZD010TAB へ挿入します。
insert into [sms].[ZD010TAB] select * from [sms].[D010TAB];
挿入されるテーブルは予め空にしてから圧縮タイプを変更して、圧縮タイプでどう変わるか見てみます。
truncate table sms.ZD010TAB;
ALTER TABLE [sms].[ZD010TAB] REBUILD PARTITION = ALL WITH ( DATA_COMPRESSION = ROW );
コピー元のテーブル D010TAB は圧縮なしで実施します。
まずは圧縮なしでの結果です。約3分19秒
メモリの使用量に違いはあったものの、時間的には大差ない結果でした。
今回は挿入を見てみます。
検索で使ったテーブル D010TAB と同じ構造のテーブル ZD010TAB を作って、
create table sms.ZD010TAB ( MASTER nvarchar(40) not null, TABNAME nvarchar(30) not null);
そこに insert into select で D010TAB の内容を ZD010TAB へ挿入します。
insert into [sms].[ZD010TAB] select * from [sms].[D010TAB];
挿入されるテーブルは予め空にしてから圧縮タイプを変更して、圧縮タイプでどう変わるか見てみます。
truncate table sms.ZD010TAB;
ALTER TABLE [sms].[ZD010TAB] REBUILD PARTITION = ALL WITH ( DATA_COMPRESSION = ROW );
コピー元のテーブル D010TAB は圧縮なしで実施します。
まずは圧縮なしでの結果です。約3分19秒
SQL Server 2008R2 データ圧縮 その③ [DBMS]
前回はどの程度圧縮されるかというのを見てみました。
今回は性能面ではどうかという事で検索性能を見てみようと思います。
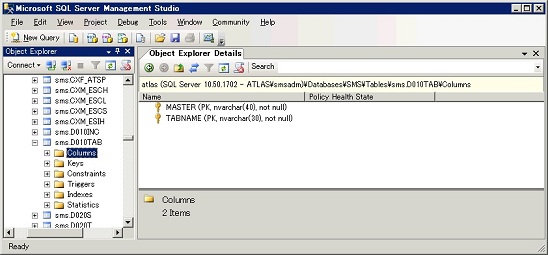
まずは対象にしたテーブルです。
カラムは2つ両方とも可変帳の文字列です。
今回は性能面ではどうかという事で検索性能を見てみようと思います。
まずは対象にしたテーブルです。
カラムは2つ両方とも可変帳の文字列です。
aki-aoki さん

-
nice! 901
記事 1283
テーマ パソコン・インターネット (17位)
プロフィール
ブログを紹介する


