この広告は前回の更新から一定期間経過したブログに表示されています。更新すると自動で解除されます。
Oracle インデックス圧縮 [DBMS]
圧縮と一言で言っても何を又は何処を圧縮するのか、Oracleの圧縮といってもいろいろあります。
とりあえず、データの圧縮とインデックスの圧縮を見て行きたいと思います。
Oracleの場合、データの圧縮とインデックスの圧縮ではアルゴリズムが全く違いますので分けて見て行きます。
まずはインデックスの圧縮です。
Oracle 8i の頃からある機能だそうです。
こんなインデックスがあった場合、
以下の様に圧縮するそうです。
同じ項目を一まとめにして実際の容量を減らします。
圧縮したからといって伸張に時間がかかるという訳ではなく、インデックスのフルスキャンの時は実際に読み込む量が減るので、多少なりとも早くなる事が期待できます。
実際検索して検証しようとは思いましたが…データが用意出来なかったので今回は無しです。
インデックスが縮小されたからといって、テーブルスペースのサイズが縮小される訳ではないので、RMANとか使わないデータベースのバックアップ(データファイルのコピー)の時間が短縮されないのがちょっと微妙です。空き容量分、データファイルのリサイズで縮小しないと短縮されません。
既存のインデックスを圧縮する場合、以下の様なDMLになります。
alter index "SAPSR3"."D010TAB~0" rebuild compress 2 tablespace PSAPSR3701 pctfree 1;
D010TAB~0 がインデックスで、SAPSR3 はスキーマ, PSAPSR3701 はテーブルスペースになります。
既存のインデックスは再構築する時に compress オプションを付けて圧縮するインデックスを作ります。compress の次に続く 2 はインデックスの何項目までをまとめるのかを指定する接頭辞といいます。
インデックス毎に項目数は違うし、何個目まででまとめるのが効率的かが違ってきます。
故に、単純に全部圧縮する訳にも行かず、1つ1つのインデックスについて何項目までをまとめたら良いかを見極めつつ圧縮する必要があります。
SAP環境のOracleでは IND_COMP パッケージなるものが追加で提供されているので、これで自動的に何項目が最適なのか調べてDMLまで作ってくれます。
ただし、分析するデータが無いインストール直後では精度が低いので要注意です。稼動後しばらくしてから分析しないと精度のよい圧縮が出来ないと思います。
さらに、SAP R/3又はERPでは経験により代表的なインデックスの接頭辞が指定されたSQLが提供されています。こちらはインストール直後から有効です。
詳しくは SAPノート1109743を参照して下さい。
実際に圧縮してみました。
その前に、テーブルやインデックスといったセグメントの大きさを調べるには USER_SEGMENTS テーブルにセグメントのサイズがあります。
また、インデックスが圧縮されているかどうかという情報は USER_INDEXES にあります。
まずは、圧縮前の情報です。
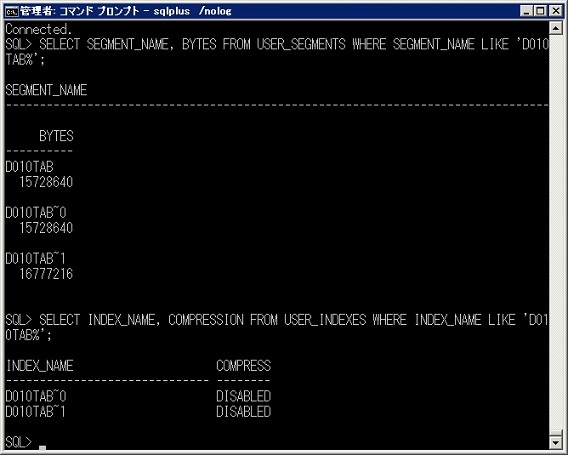
このインデックスを圧縮します。
15,728,640→8,388,608 (約53.3%)
16,777,216→12,582,912 (75%)
中身によりますが、意外と圧縮されました。
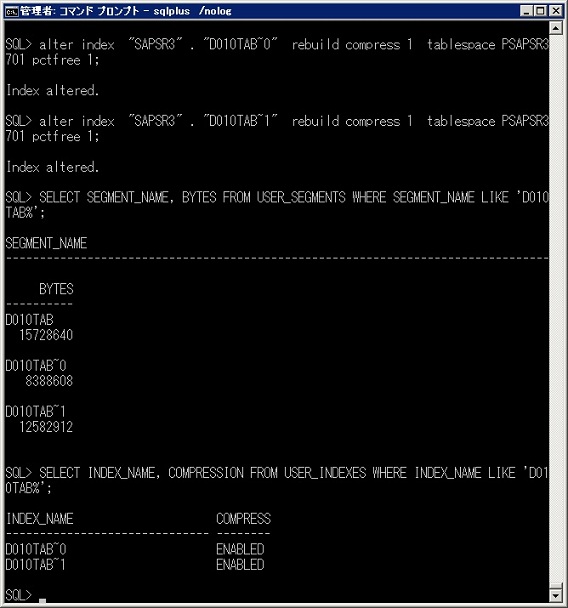
圧縮を解除する時は nocompress を指定します。
alter index "SAPSR3"."D010TAB~0" rebuild nocompress tablespace PSAPSR3701 pctfree 1;
とりあえず、データの圧縮とインデックスの圧縮を見て行きたいと思います。
Oracleの場合、データの圧縮とインデックスの圧縮ではアルゴリズムが全く違いますので分けて見て行きます。
まずはインデックスの圧縮です。
Oracle 8i の頃からある機能だそうです。
こんなインデックスがあった場合、
| 1 | A | X | 1 | A | 1 | DATA1 |
|---|---|---|---|---|---|---|
| 1 | A | X | 1 | B | 2 | DATA2 |
| 1 | A | X | 2 | A | 3 | DATA3 |
| 1 | A | Y | 1 | B | 4 | DATA4 |
| 1 | A | Y | 3 | C | 5 | DATA5 |
| 1 | A | Y | 3 | C | 6 | DATA6 |
| 1 | A | Y | 3 | D | 7 | DATA7 |
| 1 | B | X | 1 | A | 1 | DATA8 |
| 1 | B | X | 1 | A | 2 | DATA9 |
| 1 | B | X | 1 | C | 3 | DATA10 |
| 1 | B | X | 3 | A | 4 | DATA11 |
| 1 | B | X | 3 | C | 5 | DATA12 |
| 1 | B | X | 3 | C | 6 | DATA13 |
以下の様に圧縮するそうです。
| 1 | A | X | 1 | A | 1 | DATA1 |
|---|---|---|---|---|---|---|
| 1 | B | 2 | DATA2 | |||
| 2 | A | 3 | DATA3 | |||
| 1 | A | Y | 1 | B | 4 | DATA4 |
| 3 | C | 5 | DATA5 | |||
| 3 | C | 6 | DATA6 | |||
| 3 | D | 7 | DATA7 | |||
| 1 | B | X | 1 | A | 1 | DATA8 |
| 1 | A | 2 | DATA9 | |||
| 1 | C | 3 | DATA10 | |||
| 3 | A | 4 | DATA11 | |||
| 3 | C | 5 | DATA12 | |||
| 3 | C | 6 | DATA13 |
同じ項目を一まとめにして実際の容量を減らします。
圧縮したからといって伸張に時間がかかるという訳ではなく、インデックスのフルスキャンの時は実際に読み込む量が減るので、多少なりとも早くなる事が期待できます。
実際検索して検証しようとは思いましたが…データが用意出来なかったので今回は無しです。
インデックスが縮小されたからといって、テーブルスペースのサイズが縮小される訳ではないので、RMANとか使わないデータベースのバックアップ(データファイルのコピー)の時間が短縮されないのがちょっと微妙です。空き容量分、データファイルのリサイズで縮小しないと短縮されません。
既存のインデックスを圧縮する場合、以下の様なDMLになります。
alter index "SAPSR3"."D010TAB~0" rebuild compress 2 tablespace PSAPSR3701 pctfree 1;
D010TAB~0 がインデックスで、SAPSR3 はスキーマ, PSAPSR3701 はテーブルスペースになります。
既存のインデックスは再構築する時に compress オプションを付けて圧縮するインデックスを作ります。compress の次に続く 2 はインデックスの何項目までをまとめるのかを指定する接頭辞といいます。
インデックス毎に項目数は違うし、何個目まででまとめるのが効率的かが違ってきます。
故に、単純に全部圧縮する訳にも行かず、1つ1つのインデックスについて何項目までをまとめたら良いかを見極めつつ圧縮する必要があります。
SAP環境のOracleでは IND_COMP パッケージなるものが追加で提供されているので、これで自動的に何項目が最適なのか調べてDMLまで作ってくれます。
ただし、分析するデータが無いインストール直後では精度が低いので要注意です。稼動後しばらくしてから分析しないと精度のよい圧縮が出来ないと思います。
さらに、SAP R/3又はERPでは経験により代表的なインデックスの接頭辞が指定されたSQLが提供されています。こちらはインストール直後から有効です。
詳しくは SAPノート1109743を参照して下さい。
実際に圧縮してみました。
その前に、テーブルやインデックスといったセグメントの大きさを調べるには USER_SEGMENTS テーブルにセグメントのサイズがあります。
また、インデックスが圧縮されているかどうかという情報は USER_INDEXES にあります。
まずは、圧縮前の情報です。
このインデックスを圧縮します。
15,728,640→8,388,608 (約53.3%)
16,777,216→12,582,912 (75%)
中身によりますが、意外と圧縮されました。
圧縮を解除する時は nocompress を指定します。
alter index "SAPSR3"."D010TAB~0" rebuild nocompress tablespace PSAPSR3701 pctfree 1;

aki-aoki さん

-
nice! 901
記事 1283
テーマ パソコン・インターネット (10位)
プロフィール
ブログを紹介する



難しいな… (^00^)
by musselwhite (2011-08-11 10:13)